ai-agents-metrics
![]()




Analyze your AI agent work history. Track spending. Optimize your workflow.
AI is writing more of your code. You still don’t know:
- How many attempts each task actually takes
- Where the process breaks down and why
- Whether your workflow is getting faster or generating more rework
ai-agents-metrics extracts these signals from your existing Claude Code or Codex history — no manual setup required. Point it at your history files and see what’s happening: retry pressure, token cost, session timeline. For richer tracking, add explicit goal boundaries and outcome labels on top.
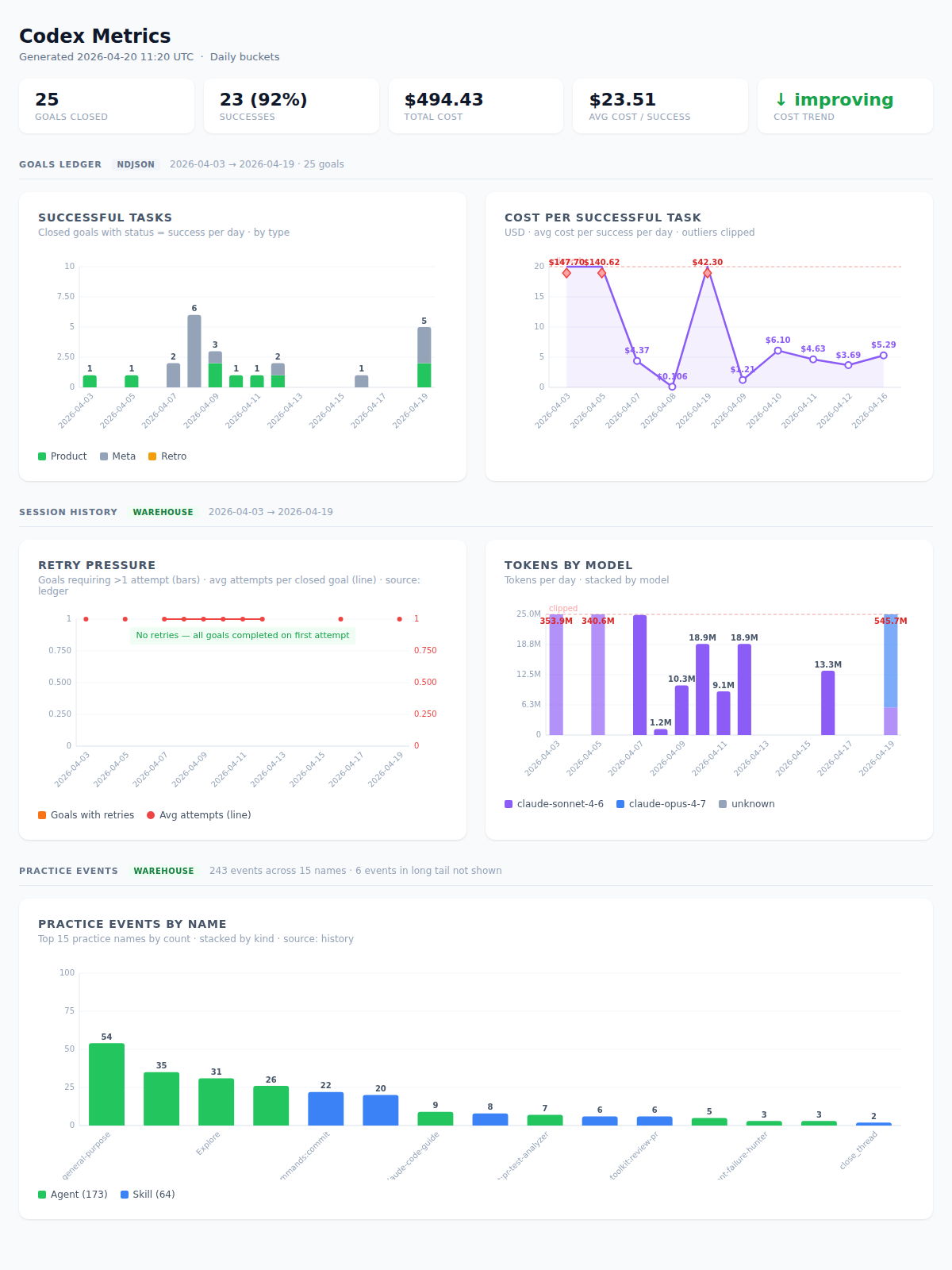
Running this on 6 months of Claude Code + Codex history (3.85B tokens, 160 threads) surfaced:
- 100% of Claude “retries” are subagent spawns, not user retries —
attempt_count > 1is structural, not a failure signal (F-001)- Subagent delegation halves main-session tokens within-thread — median 2.05× compression, p = 0.000456 (F-007)
- Per-skill compression ranking —
Explore2.63×,code-reviewer3.25×,commit0.72× (F-008)Full index: docs/findings/. N=1 developer; the mechanisms generalize because they come from the tools, not the data.
Quick start
pipx install ai-agents-metrics
ai-agents-metrics history-update # reads ~/.codex + ~/.claude by default
ai-agents-metrics show # retry pressure, cost, session timeline
ai-agents-metrics render-html # interactive HTML report
Non-default history paths, full command list, and manual goal tracking (optional): CLI reference.
What you get
- History extraction — retry pressure, token cost, model usage from existing session files. No setup.
- HTML report — one self-contained file, summary strip + 5 trend charts, opens in any browser.
- Optional manual tracking — add goal boundaries and outcome labels on top of history for per-task breakdowns.
Not a benchmark, not an eval framework, not a model comparison tool. It is a local analysis tool for real engineering work done with AI.
Privacy
All data stays local. Writes only to:
.ai-agents-metrics/warehouse.db— local SQLite warehouse used by the history pipelinemetrics/events.ndjson— append-only event log for manual goal tracking (opt-in)docs/ai-agents-metrics.md— optional markdown export (regenerated on demand)
No data is sent to any remote service.